Should I use a single LevelDB or many to hold my data?
This is a long overdue post, so long in fact that I can't remember who I promised to do this for! Regardless, I keep on having discussions around this topic so I thought it worthwhile putting down some notes on what I believe to be the factors you should consider when making this decision.
What's the question?
It goes like this: You have an application that uses LevelDB, in particular I'm talking about Node.js applications here but the same would apply if you're using LevelUP in the browser and also most of the other back-ends for LevelUP. And you invariably end up with different kinds of data, sometimes the kinds of data you're storing is so different that it feels strange putting them into the same storage blob. Often though, you just have sets of not-very-related data that you need to store and you end up having to make a decision: do I put everything into a single LevelDB store or do I put things into their own, separate, LevelDB store?
This stuff doesn't belong together!
Coming from an relational database background, it took me a little while to displace the concept of discrete tables with the notion of namespacing within the same store. I can understand the temptation to want to keep things separate, not wanting to end up with a huge blob of data that just shouldn't be together. But this isn't the relational database world and you need to move on!
We have a set of LevelUP addons, such as sublevel, that exist mainly to provide you with the comfort of being able to separate your data by whatever criteria makes sense. bytewise is another tool that can serve a similar purpose and some people even use sublevel and bytewise together to achieve more complex organisation.
We have the tools at our disposal in Node.js to turn a one-dimensional storage array into a very complex, multidimensional storage system where unrelated, and semi-related data can coexist. So, if the only reason you want to store things in separate stores is because it just feels right to do so, you should probably be looking at what's making you think that way. You may need to update your assumptions.
Technical considerations
That aside, there are some technical considerations for making this decision:
Size and performance
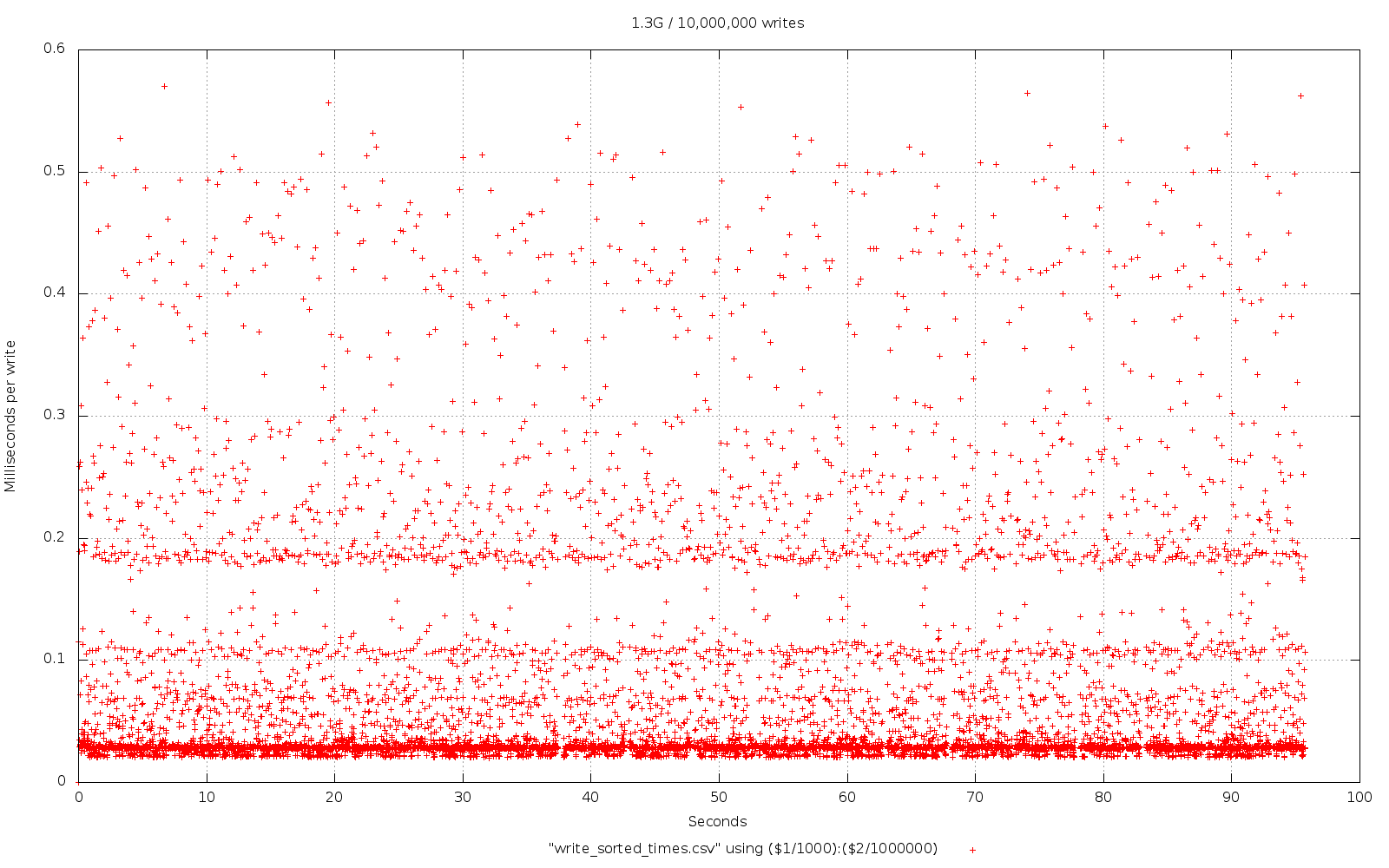
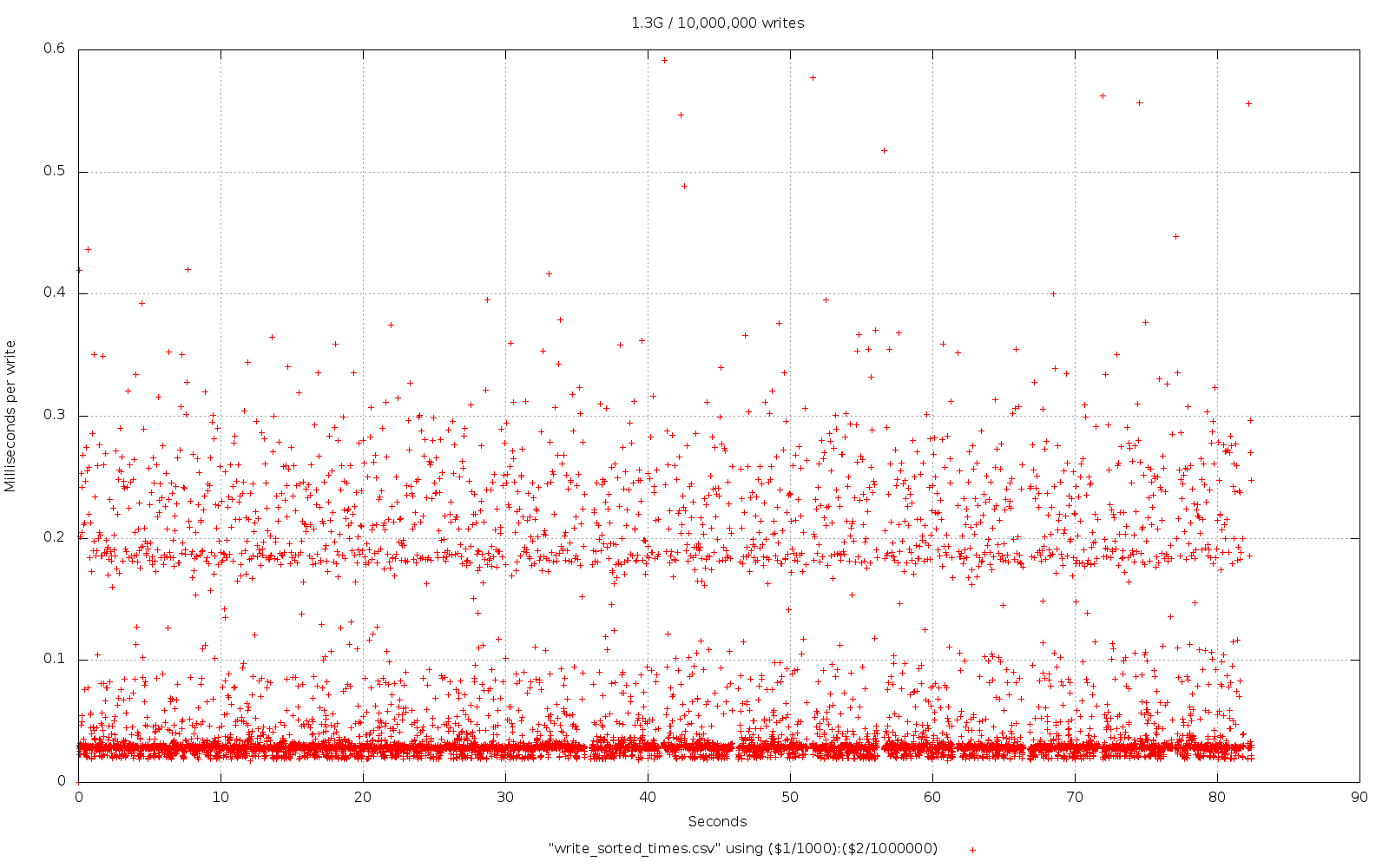
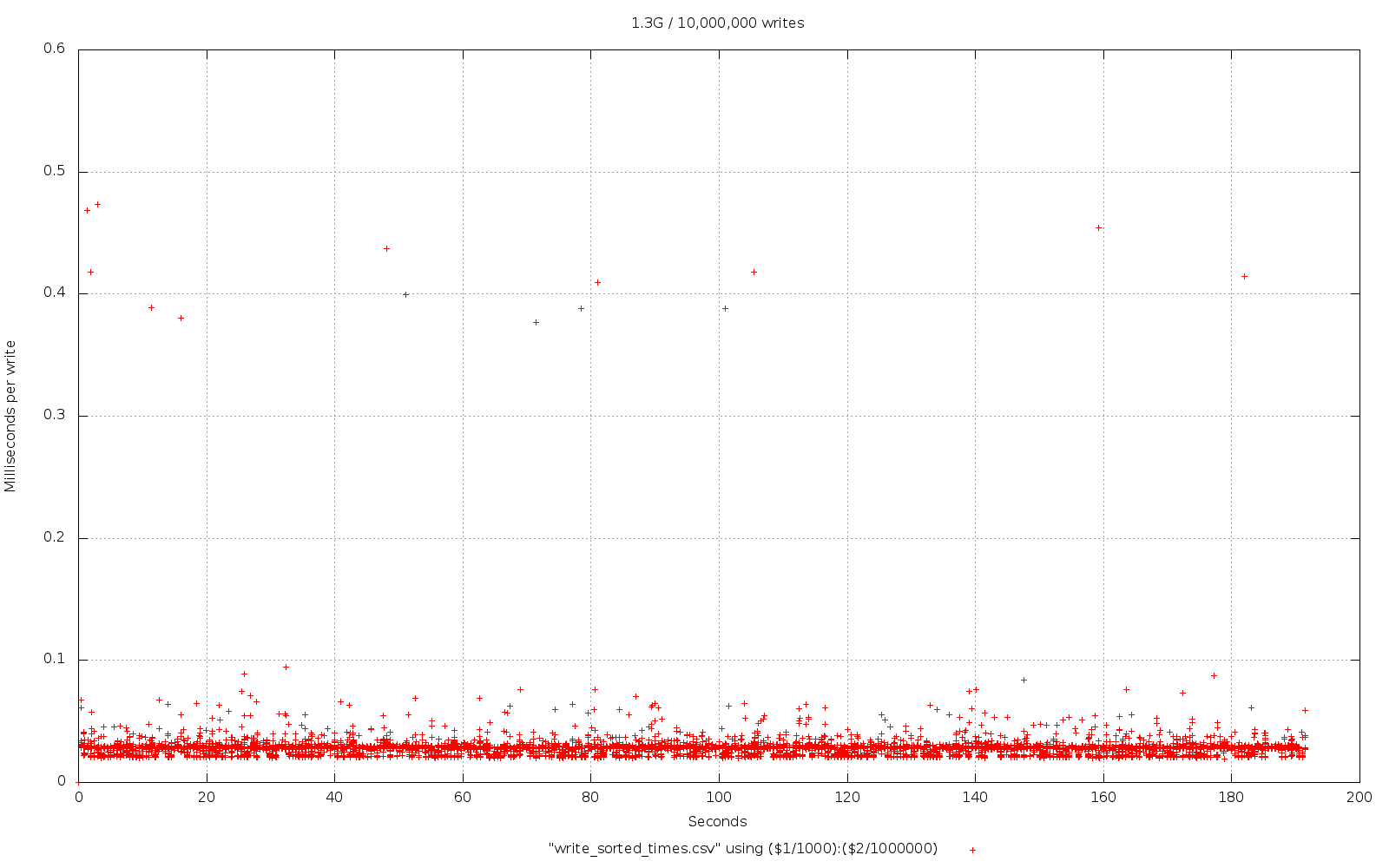
To be clear, LevelDB is fast and it can also store lots of data, it'll handle Gigabytes of data without too much sweat. However, there are some performance concerns when you start getting in to the Gigabyte range, mainly when you're trying to push data in at a high rate. Most use-cases don't do this so be honest about your performance needs. For most people LevelDB is simply fast.
However, if you do have a high-throughput scenario involving a large amount of data that you need to store then you may want to consider having a separate store to deal with the large data and another one to deal with the rest of your data so the performance isn't impacted across the board.
But again, be honest about what your workload is, you're probably not pushing Voxer amounts of data so don't prematurely optimise around the workload you'd like to think you have or are going to have one day in the distant future.
Cache
Caching is transparent by default with LevelDB so it's easy to forget about it when making these kinds of decisions but it's actually quite important for this particular question.
By default, you have an 8M LRU cache with LevelDB and all reads use that cache, for look-ups and also for updating with newly read values. So, you can have a lot of cache-thrash unless you're reading the same values again and again.
But, there is a fillCache (boolean) option for read operations (both get() and createReadStream() and its variations). So you can set this to false where you know you won't be needing fast access to those entries again and you don't want to push out other entries from the LRU.
So caching strategies can be separate for different types of data and are not a strong reason to keep things in a separate data store.
I always recommend that you should tinker with the cacheSize option when you're using LevelDB, it can be as large as you want to fit in the available memory of your machine. As a rule of thumb, somewhere between 2/3 and 3/4 of the available memory should be a maximum if you can afford it.
Consider though what happens if you are using separate LevelDB stores, you now have to deal with juggling cacheSize between the stores. Often, you're probably going to be best served by having a single, large cache that can operate across all your data types and let the normal behaviour of your application determine what gets cached with occasional reliance on 'fillCache': false to fine-tune.
Consistency
As I discussed in my LXJS talk, the atomic batch is an important primitive for building solid database functionality with inherent consistency. When you're using sublevel, even though you have what operate like separate LevelUP instances for each sublevel, you still get to perform atomic batch operations between sublevels. Consider indexing where you may have a primary sublevel for the entries you're writing and a secondary sublevel for the indexing data used to reference the primary data for lookups. If you're running these as separate stores then you lose the benefits of the atomic batch, you just can't perform multiple operations with guaranteed consistency.
Try and keep the atomic batch in mind when building your application, instead of accepting the possibility of inconsistent state, use the batch to keep consistency.
Back-end flexibility
OK, this one is a bit left-field, but remember that LevelUP is back-end-agnostic. It's inspired by LevelDB but it doesn't have to be Google's LevelDB that's storing data for you. It could be Basho's fork or HyperLevelDB. It could even be LMDB or something a little crazy like MemDOWN or mysqlDOWN!
If you're at all concerned about performance, and most people claim to be even though they're not building performance-critical applications, then you should be benchmarking your particular workload against your storage system. Each of the back-ends for LevelUP have different performance characteristics and different trade-offs that you need to understand and test against your needs. You may find that one back-end works for one kind of data in your application and another back-end works for another.
Summary
The TL;DR is: in most cases, a single LevelDB store is generally preferable unless you have a real reason for having separate ones.
Have I missed any considerations that you've come across when making this choice? Let me know in the comments.