LevelDOWN Alternatives
Since LevelUP v0.9, LevelDOWN has been an optional dependency, allowing you to switch in alternative back-ends.
We have MemDOWN, a pure in-memory data-store, allowing you to run LevelUP against transient, and very fast storage.
We also have level.js which works against IndexedDB, allowing you to run LevelUP in the browser!
Since LevelUP just needs some basic primitives and a sorted bi-directional iterator, we can swap out the back-end with numerous alternatives.
The easy targets are the forks of LevelDB that purport to fix or improve LevelDB in some way. I have another post brewing on what I think about the claims made in this area and how we ought to approach them, but that can come later. For now I have some packages in npm for you to try for yourself!
Basho
First of all we have leveldown-basho which bundles the Basho LevelDB fork into LevelDOWN. See Matthew Von-Maszewski's slides from the recent Ricon East 2013 for more information on what they've tried to do with LevelDB.
In summary, Basho's aim is to optimise LevelDB "for the server", particularly for high write throughput. They use >1 compaction threads and relax the rules a little on overlapping keys for the lower levels. Plus a few other things that I won't get in to here.
$ npm install levelup leveldown-basho
var levelup = require('levelup')
, leveldown = require('leveldown-basho')
, db = levelup('/path/to/db', { db: leveldown })
// go to work on `db`
Disclaimer: some of the LevelDOWN and LevelUP tests are failing on the current build for this release, although I don't believe they should impact on standard usage but your mileage may vary...
HyperDex
Next, we have leveldown-hyper, which bundles a fork by the people behind HyperDex, a key-value store. Again their aim is to optimise LevelDB for a server environment. You can see some of their claims about performance here. I don't know as much about this fork, I'll investigate further when I have time, but they are also using multiple compaction threads to do the background work.
$ npm install levelup leveldown-hyper
var levelup = require('levelup')
, leveldown = require('leveldown-hyper')
, db = levelup('/path/to/db', { db: leveldown })
// go to work on `db`
Lies! Benchmarks!
OK, benchmarks kind of suck, particularly microbenchmarks. It's really hard to test something that's meaningful for everyone's use-case. But you can make pretty pictures with them and they can tell something of a story, even if it's just the first page of a novel.
So here we go. I've put together a simplistic benchmark that tries to test the kind of situation that these two forks are aiming to optimise for. In particular, high-throughput writes. There's a common claim that LevelDB has problems with writes because the compaction thread can hold up levels 0 and 1 while it's working on higher levels; and you really want to be flushing the new data as soon as possible so you can get more in. (Again, I have more to say on this & the claims about "fixing" the problem in a later post).
I have a sorted-write benchmark in the LevelDOWN repo that tries to push in 10M pre-sorted entries as fast as possible, fully utilising Node's worker-threads for the job. So this isn't your typical browser scenario. An important point here is that Node is a unique environment when looking at LevelDB performance. It's not going to be a straightforward mapping of benchmark results obtained with other LevelDB bindings onto what we can achieve in Node.
Because there are so many entries, instead of recording the time for individual writes, I've recorded average time for batches of 1000 writes. Below you can see what the write-times look like when plotted over time. There are a bunch of outliers that are above the maximum Y of 0.6ms, but not enough to warrant distracting from the interesting behaviour below 0.6ms so I chopped it off there.
It is important to note that I'm using the default options here and this is where I'll probably cop some flak. Basho in particular advocate a healthy amount of "tuning" to achieve appropriate performance. In particular the write-buffer defaults to only 4M and you can push data in faster (at the cost of compactions later on) by increasing this. I think the forks may even have additional tunables of their own that you can fiddle with. But, this whole tuning thing is a rabbit hole I don't dare go down right now!
I'm running this on an i7-2630QM CPU, plenty of RAM and an SSD.
You can see that we managed to push in the 10M entries in just over 95 seconds with the plain Google LevelDB (v1.10.0).
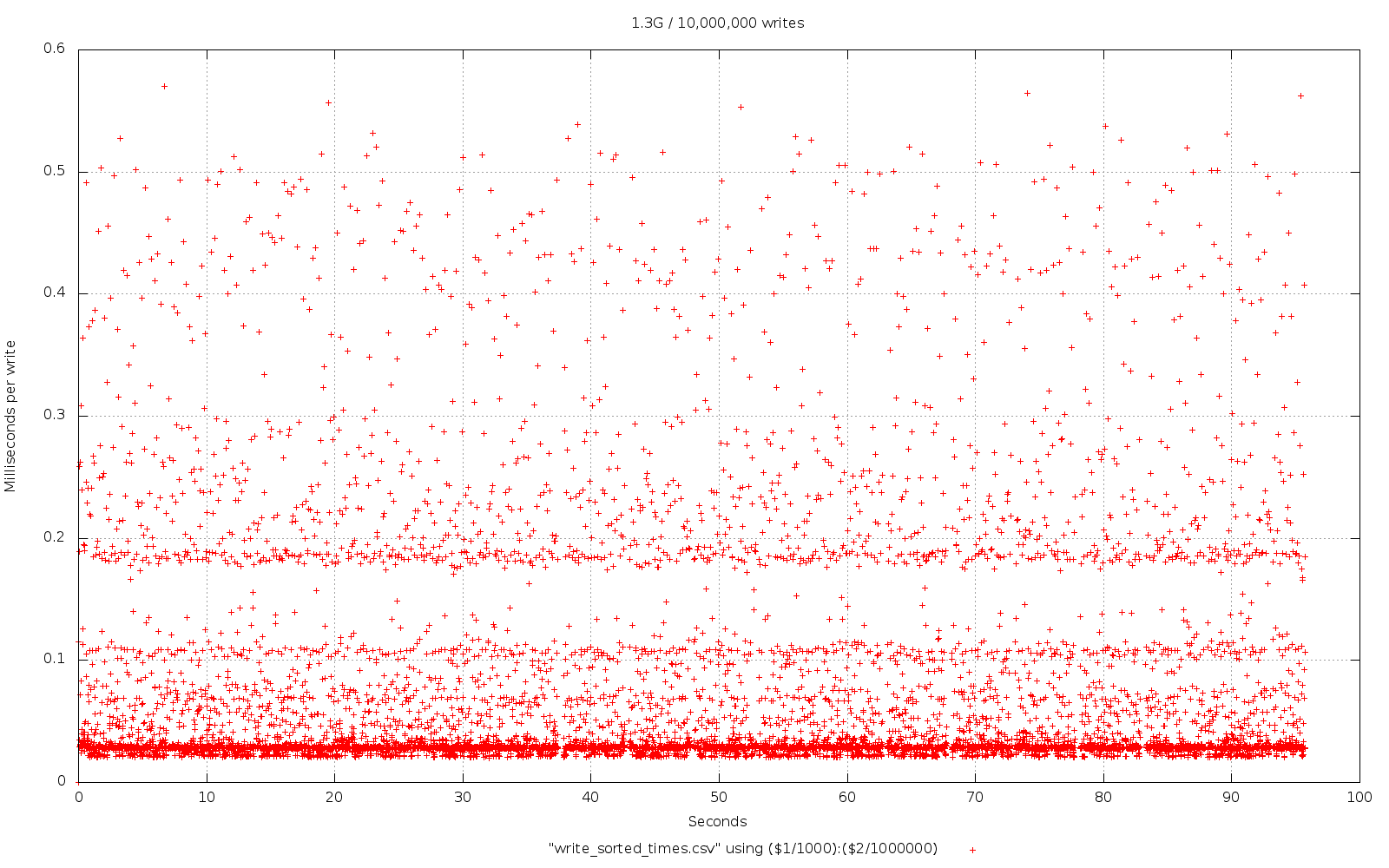
Next up we have the HyperDex fork. The main difference here is that we have it working slightly faster in total and the write-times have been trimmed down a bit to be more consistent. Not a bad effort with default settings, quite a nice picture.
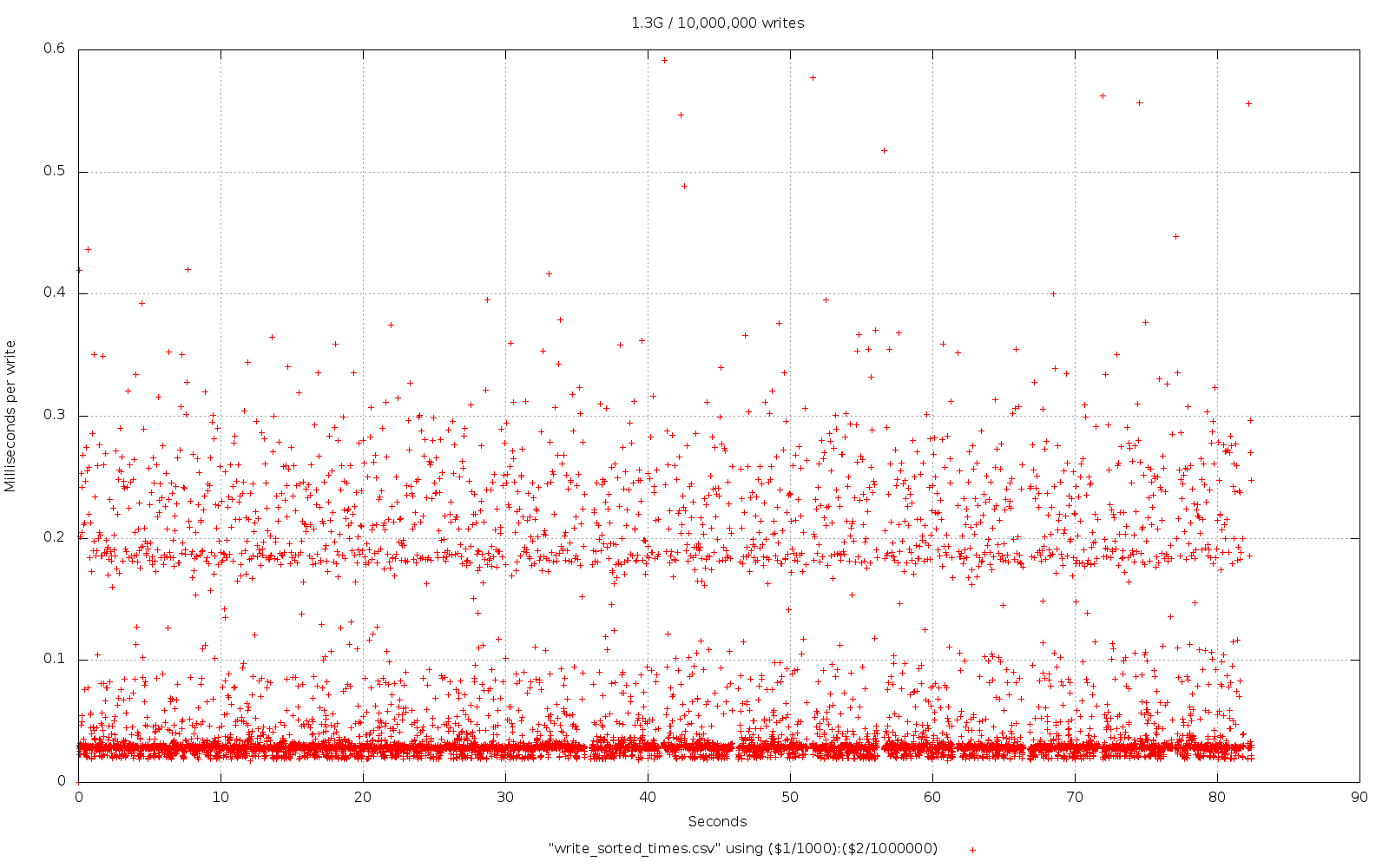
Lastly we can see what Basho have done. They've been on this case for a lot longer than HyperDex have and their fork, internally at least, diverges quite a bit from Google's LevelDB.
We can see that the write-time has been considerably flattened; which is in line with what Basho claim and are aiming for, the consistency here is very impressive. Unfortunately we've ended up with a total time that is double what it took Google's LevelDB to get the 10M entries in!
No doubt this is probably something to do with the tunables, or perhaps I've messed something up, anything's possible!
So?
If you take anything away from this, here's what I think it should be: Do your own benchmarks if performance really is an issue for you. You're going to need some kind of benchmark suite that is tailored to your particular application. This will not only let you choose the appropriate storage system but it will give you something to work with when you start to get in to the mire that is "tunables".
It's likely I won't be able to leave this alone and will be posting more benchmarks with some tweaking and tuning. I'd love to have input from others on this too of course! The code for this is all in the LevelDOWN repo with both of these forks under appropriately named branches.